Modul: Was braucht es für eine Datenpublikation?
| Website: | ORCA.nrw |
| Kurs: | Grundwissen: Datenmanagement in Studium & wissenschaftlicher Praxis |
| Buch: | Modul: Was braucht es für eine Datenpublikation? |
| Gedruckt von: | Gast |
| Datum: | Mittwoch, 8. April 2026, 02:20 |
Über dieses Modul

Hier erfahren Sie etwas über den Weg zu einer Datenpublikation und über wichtige Konzepte, die man dazu kennen sollte.
- Repositorien
- FAIR-Prinzipien
- Persistente Identifikatoren
- Metadaten
Lernziel (Wissen): Die
Studentinnen und Studenten kennen Speicherorte für die Veröffentlichung von
Forschungsdaten.
Lernziel (Verstehen): Die
Studentinnen und Studenten können die Grundzüge der FAIR-Prinzipien wiedergeben.
Lernziel (Wissen): Die
Studentinnen und Studenten kennen Konzepte zur Auffindbarkeit und Beschreibung digitaler Daten.
Bearbeitungsdauer: ≈ 35 Min.
Vor einer Datenpublikation
| Professor Dr. Durchblick und sein Team haben beträchtliche Fortschritte in ihrem Forschungsprojekt erzielt. Ein erster Fachartikel, welchen Sie bereits mit einem kleinen Datensatz im Rohdaten veröffentlichten, erzeugte bei Fachkolleginnen und -kollegen bereits positive Resonanz. Derzeit befinden sie sich in den Vorbereitungen für eine eigenständige Veröffentlichung ihrer Forschungsdaten. |  |
Was bisher geschah |
|
|---|---|
| |
Bereits in der Planungsphase des Forschungsprojekts haben sie einen Datenmanagementplan erstellt, der festlegt, wie die entstehenden Forschungsdaten gesammelt, verarbeitet, analysiert, archiviert und veröffentlicht werden sollen. |
| Während der Erhebungsphase haben sie mit großer Sorgfalt darauf geachtet, die Richtigkeit der Daten zu gewährleisten, und gleichzeitig die Schritte zur Herstellung der Daten detailliert dokumentiert. | |
| In der Analysephase haben sie übliche fachliche Standards und anerkannte Methoden verwendet. Im Projektteam legten sie besonderen Wert auf eine einheitliche Dokumentation hinsichtlich der Daten- und Dateibenennung und sie hielten die einzelnen Schritte ihrer Vorgehensweise bei der Analyse fest. | |
| Dank ihrer frühzeitigen Überlegungen zur langfristigen Aufbewahrung ihrer Forschungsergebnisse und der Auswahl archivfähiger Dateiformate war die Archivierung der Rohdaten in ihrer Einrichtung unproblematisch. |
Ausschlusskriterien für eine Veröffentlichung

Die Einhaltung rechtlicher Regelungen obliegt den Wissenschaftlerinnen und Wissenschaftlern. So prüfen sie, ob es Gründe gibt, die gegen eine Veröffentlichung sprechen, wie z. B. diese:
| Personenbezogene
Daten Manchmal dürfen Forschende persönliche Daten nur speichern, nicht aber veröffentlichen, z. B. wenn die Teilnehmerinnen und Teilnehmer von Studien nur der Speicherung zugestimmt haben. |
||
|---|---|---|
| Urheberrechtlich geschützte Daten Daten, die durch das Urheberrecht geschützt sind, dürfen oft nicht veröffentlicht werden, z. B., wenn die Urheberinnen oder Urheber der Nutzung und Veröffentlichung von Archivmaterial nicht zugestimmt haben. |
||
 |
Vertragsklauseln
mit Partnern Forschende können z. B. Verträge mit Industriepartnern haben, welche die Datenveröffentlichung ausschließen, um z. B. Firmengeheimnisse zu schützen. |
|
| Beurteilung durch
Ethikkommission Eine Ethikkommission kann aus besonderen Sicherheitsgründen von der Veröffentlichung abraten, zum Beispiel bei Bauanleitungen für Waffen oder Rezepturen für Kampfstoffe. |
Dieser Text wurde übernommen aus auf dem Kapitel Einführung in das Forschungsdatenmanagement (Hessische Forschungsdateninfrastruktur, 2022)
Wo werden Daten publiziert?
Repositorien
Digitale Daten werden üblicherweise in Repositorien publiziert. Ein Repositorium ist ein digitaler Speicherort für verschiedene Arten von digitalen Informationsobjekten, wie zum Beispiel Publikationen oder Forschungsdaten. Es ermöglicht den Zugang zu diesen Informationsobjekten für die Öffentlichkeit oder einen bestimmten Nutzerkreis. In einigen Fällen prüfen Kuratorinnen und Kuratoren die Daten vor der Aufnahme in das Repositorium auf ihre Qualität und die Einhaltung rechtlicher Bedingungen, um sicherzustellen, dass sie in der vorliegenden Form von Dritten genutzt werden können. (Vgl. Universität Konstanz, o. J.c ) Häufiger erfolgt eine technische Qualitätssicherung, sowie die Prüfung auf Virenfreiheit der digitalen Informationsobjekte.
Forschungsgrundlagen und -ergebnisse verfügbar machen
Auswahl eines Repositoriums

Bereits in der Planungsphase ihres Forschungsprojekts hatte sich die Forschergruppe für ein fachspezifische Repositorium entschieden, da sie hierdurch die größtmögliche Reichweite innerhalb ihrer Fachgemeinschaft erzielen.
Drei Arten von Repositorien
| fachspezifisches Repositorium | multidisziplinäres Repositorium | institutionelles Repositorium |
| Bündeln
thematisch zu einem speziellen Fachgebiet und verwenden häufig fachspezifische Standards zur Datenbeschreibung oder Dateiformaten. |
Sind thematisch breit
aufgestellt und fördern den Informationsaustausch zwischen verschiedenen
Disziplinen. |
Beinhaltet die Forschungsdaten
einer Einrichtung und beachtet deren Richtlinien. Eignen sich besonders gut, um die öffentliche Sichtbarkeit der Forschung einer Einrichtung zu fördern. |
| Beispiel: Portal für medizinische Datenmodelle [https://medical-data-models.org] |
Beispiel: Zenodo [https://zenodo.org] |
Beispiel: Repositorium Universität Würzburg [https://wuedata.uni-wuerzburg.de] |
Beachtung der FAIR Prinzipien

Die Beschreibung von Datensätzen und digitalen Suchsystemen, um Forschungsdaten langfristig zugänglich zu machen, erfolgt unter Berücksichtigung der FAIR-Prinzipien, die die technischen Anforderungen beschreiben. Dr. Durchblick und seine Team haben das natürlich im Griff.
Qualitätskriterien für digitale Datenaustausch
| Findable |
Accessible | Interoperable | Reusable |
| Daten sind leicht auffindbar |
Daten sind zugänglich |
Daten sind zwischen verschiedenen technischen Systemen verwendbar | Daten sind nachnutzbar |
Die Daten verfügen über ausreichende Beschreibungen mit relevanten Metadaten und werden mittels eines klaren, dauerhaften Identifikatoren referenziert. |
Die Daten sind sowohl für menschliche als auch maschinelle Lesbarkeit
ausgelegt und werden in einem zuverlässigen Repositorium aufbewahrt. |
Verbreitete, offene Dateiformate, die Einhaltung fachlicher Standards und ein einheitliches Vokabular erleichtern die Nachnutzung. |
Die Daten sind durch eine klare Lizenz geschützt, enthalten präzise Information zur Herkunft und sind umfassend dokumentiert |
Dieser Text wurde übernommen aus auf dem Kapitel Einführung in das Forschungsdatenmanagement (Hessische Forschungsdateninfrastruktur, 2022)
To Do: FAIR vs. OPEN
Detail: Was sind Persistente Identifikatoren?

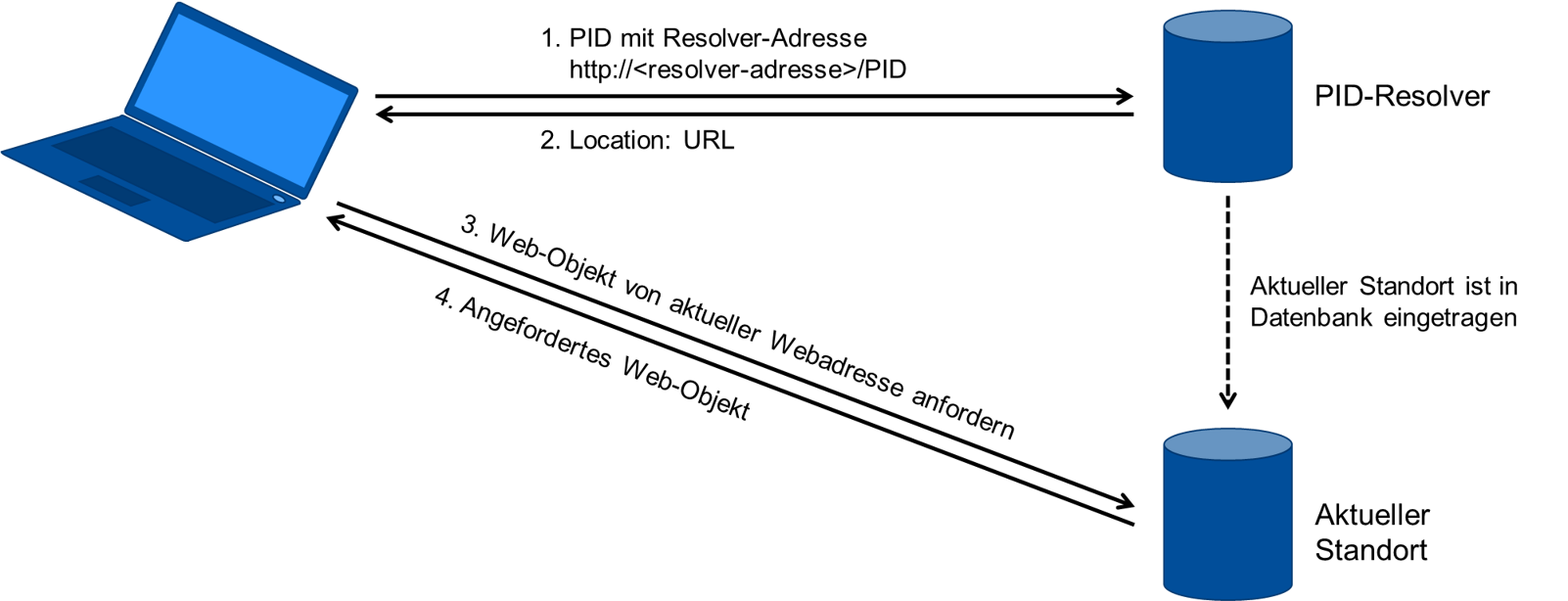
Funktionsprinzip PID Systeme
Alle
PID-Systeme funktionieren nach einem ähnlichen Prinzip. Wichtig hierbei sind die sogenannten Resolver, die eine PID in die aktuelle URL "auflösen" können. Ein Resolver ist eine Software, die in einer Adressdatenbank für persistente Identifikatoren, den aktuellen Standort und die mit der PID gespeicherten Metadaten abfragen kann.
Schritte des Resolvings
Zunächst wird der aktuelle Standort über eine resolver-adresse abgefragt (1), es erfolgt eine Rückmeldung über die URL-Adresse des aktuellen Standorts mit dem Präfix "Location:" (2), "Location:" löst eine automatische Anforderung des Informationsobjekts aus (3), abschließend wird der Zugang zum angeforderten Informationsobjekt zurückgegeben (4).
To Do: PID Resolving

- Untersuchen Sie die gegebene und die zurückgemeldete Webadressen?
- Worin unterscheiden sich diese?
- Worin unterscheiden sich diese?
- Welche Institution verbirgt sich hinter dem genutzten Resolving Dienst?
- Welche Bezeichnung haben die Identifikatoren, die dort vergeben werden?
- Welche Bezeichnung haben die Identifikatoren, die dort vergeben werden?
Normdaten
Identifikation von Personen, Institutionen, usw. ..
Es gibt verschiedene Arten von Identifikatoren, die
innerhalb des Wissenschaftsbetriebs üblich sind. So gibt es beispielsweise Identifikatoren für Publikationen oder Personen, aber auch solche für Sachbegriffe, Geografika und Institutionen, wie beispielsweise die Codes der Gemeinsame Normdatei. Normdaten sind besonders wichtig für die Strukturierung von Information, erleichtern die Suche und
Vernetzung von Wissen sowie die langfristige Verweisbarkeit
wissenschaftlicher Ressourcen.
Das folgende Video Was sind Normdaten? (Sächsische Landesbibliothek – Staats- und Universitätsbibliothek Dresden, 2023) erklärt Normdaten sehr anschaulich:
(Sächsische Landesbibliothek – Staats- und Universitätsbibliothek Dresden, 2023)DOI (Digital Objekt Identifier)

Identifikation von Publikationen
ToDo: Resolving URL DOI
ORCID (Open Researcher and Contributor ID)

Identifikation von Autorinnen und Autoren
Die ORCID iD fungiert als standardisierter und weitverbreiteter Persistenter Identifikator für die Personenkennung von wissenschaftlichen Autorinnen und Autoren. Sie dient z. B. zur treffsicheren Zuordnung von Publikationen und Personen. ORCID-IDs werden zentral durch die Organisation ORCID verwaltet. Jede Wissenschaftlerinnen und jeder Wissenschaftler kann sich selbsttätig eine ORCID-ID anlegen und auch Sie als Studierende können sich bereits registrieren.

ToDo: Recherche ORCID
- Suchen Sie z. B. nach Ihren Professorinnen und Professoren, oder nach Forscherinnen und Forschern, deren Arbeiten Sie gerade beschäftigen.
- Welche Information wird in den Profilen der Personen aufgeführt?
- Oder suchen Sie gezielt nach der Person mit der ORCID-ID [0000-0002-1335-4022]. Sie hat etwas mit Marie Curie gemeinsam und gehört damit zu einem sehr exklusiven Kreis. Finden Sie die Gemeinsamkeit heraus.

Detail: Was sind Metadaten?

Wozu sind sie wichtig?
Metadaten sind wichtig, für die inhaltserschließende Beschreibung und Dokumentation von Daten und Datensätzen, sowie für die maschinell und automatisiert Verarbeitung. Metadaten geben z. B. Information über Inhalt, Herkunft oder Format einer Ressource und lassen sich anhand solcher Information in digitalen Suchsystemen finden.
Wie werden sie verzeichnet?
Differenzierung von Metadaten
Metadaten lassen sich ihrer Funktion nach differenzieren in:
| deskriptiv | inhaltliche Beschreibung, z. B. Angabe zu Urheberinnen und Urhebern |
| strukturell | Beschreibung der Struktur eines Datensatzes, z. B. Spaltenbezeichnung in Tabellen |
| administrativ | Angabe zur Verwaltung, z. B. Datum- oder Versionsangabe |
| rechtlich | Angabe zu rechtlichen Aspekten, z. B. Lizenzinformation |
| technisch | Verarbeitungsparametern zur digitalen Verarbeitung, z. B. Dateiformat oder Dateigröße |
Standards und Normierung
Beispielszenario

Verwendung von Metadatenstandards

Beispiele
| Disziplin | Standards |
|---|---|
| fachübergreifend | https://schema.datacite.org/, https://www.dublincore.org/, https://wiki.dnb.de/page/viewpage.action?pageId=131991608, https://www.radar-service.eu/de/ueber-uns |
| Geisteswissenschaften | https://www.loc.gov/ead, https://tei-c.org/guidelines/p5, https://dariah-eric.github.io/lexicalresources/pages/TEILex0/TEILex0.html |
| Geowissenschaften | http://aims.fao.org/standards/agmes, https://www.fgdc.gov/metadata/csdgm-standard |
| Klimawissenschaften | http://cfconventions.org |
| Kunst- & Kulturwissenschaften | http://www.getty.edu/research/publications/electronic_publications/cdwa/index.html, http://www.heritage-standards.org.uk/midas-heritage |
| Naturwissenschaften | https://www.iucr.org/resources/cif/spec, http://icatproject-contrib.github.io, https://dwc.tdwg.org |
| Sozial- und Wirtschaftswissenschaften | https://ddialliance.org |
Beispiele für Thesauri sind
Art & Architekture Thesaurus [https://www.getty.edu/research/tools/vocabularies/aat/]
Standard Thesaurus Wirtschaft [https://www.zbw.eu/stw/version/latest/about.de.html]